Розбираємо, чому ручне тестування стає стратегічним, а знання архітектури коду — обов’язковим квитком у професію QA. Дізнайся, як не стати жертвою автоматизації, а очолити її.
Ще кілька років тому автоматизація означала нескінченне написання скриптів та виправлення локаторів. Сьогодні платформи на кшталт Applitools, Tricentis та QA Wolf самі знаходять баги, лагодять тести й аналізують ризики. Частина перевірок, яку раніше QA-команда виконувала вручну, тепер автоматично запускається після зміни коду або оновлення інтерфейсу.
На цьому тлі виникає логічне питання — професія QA зникає? Насправді змінюється не потреба в тестувальниках, а набір навичок, за які ринок навіть готовий платити більше.
Що таке AI-driven testing
AI-driven testing — це підхід до тестування, у якому частину рутинних QA-процесів виконує штучний інтелект: від створення тестових сценаріїв до аналізу нестабільних перевірок після змін у продукті.
Якщо класична автоматизація працює за жорстко прописаним сценарієм, то AI-система здатна адаптуватися до змін у коді, структурі сторінки або поведінці інтерфейсу без повного переписування тесту.
Головна відмінність у тому, що раніше інженер з автоматизації вручну визначав кожен баг, логіку перевірки й умови проходження сценарію. Тепер AI аналізує DOM-структуру, поведінку елементів, історію попередніх запусків і сам підказує, де тест нестабільний або який сценарій варто додати після нового релізу. Саме тому у професійному середовищі AI-driven testing часто називають наступним етапом після класичної automation.
Для кращого розуміння трансформації варто поглянути на структуру самого процесу:
Підхід
Як створюються тести
Що потребує постійного контролю
Manual testing
Спеціаліст виконує кожну перевірку вручну
Кожен цикл тестування та регресії
Automation testing
Інженер розробляє та підтримує тестовий код
Регулярна підтримка та оновлення скриптів
AI-driven testing
Система автономно генерує та коригує перевірки
Стратегічний контроль логіки та аналіз
Особливо помітною перевага AI стала там, де інтерфейс часто змінюється. Наприклад, якщо після оновлення кнопка змінила CSS-ідентифікатор, звичайний автотест часто падає. AI-модель у такій ситуації може знайти той самий елемент за контекстом: положенням на сторінці, текстом, поведінкою або сусідніми об’єктами.
Саме на цьому принципі працюють сучасні AI-рішення: вони не просто запускають перевірку, а поступово накопичують поведінкову модель продукту. І тепер, коли базове визначення зрозуміле, логічно перейти до головного питання: чому саме зараз AI так швидко зайшов у тестування і чому індустрія QA почала змінюватися значно швидше, ніж прогнозували ще два роки тому.
Сьогодні межа між розробкою та контролем якості стає дедалі тоншою — ринку потрібні фахівці, здатні працювати на обох рівнях. Приєднуйся до курсу «Fullstack розробник», щоб опанувати інструменти розробки повного циклу та навчитися керувати складними AI-системами через розуміння їхньої внутрішньої структури. Ти отримаєш технічну базу, яка перетворить тебе з виконавця тестів на стратега, здатного проєктувати надійні цифрові продукти з нуля.
AI-driven testing без міфів: де закінчується маркетинг і починається реальність
Навколо впровадження штучного інтелекту в QA існує дві крайнощі: сліпа віра в повну автоматизацію та страх масових звільнень. Розберемося з головними міфами, спираючись на технічні обмеження моделей.
Міф 1: AI самостійно знайде всі логічні баги
Це найнебезпечніша ілюзія. AI-моделі (LLM) працюють на основі ймовірностей, а не глибокого розуміння сенсу бізнесу.
Алгоритм підтвердить, що форма реєстрації технічно відправляється. Проте він не з’ясує, чи відповідає логіка нарахування податків у кошику законодавству ЄС, якщо ви не навчили його цьому заздалегідь. Згідно з World Quality Report 2025-26, близько 30% критичних дефектів у складних доменах (FinTech, MedTech) досі виявляються лише через людське розуміння контексту.
Міф 2: Тестувальнику більше не потрібно знати код
Помилково вважати, що Low-code інструменти з AI повністю витіснять розробку тестів. Насправді вимоги до технічної бази QA-інженерів лише зросли.
Для валідації коду, який згенерував AI, необхідно розуміти архітектуру системи. Спеціаліст стає «арбітром», який перевіряє нейромережу на наявність Security Vulnerabilities (вразливостей) або неефективних запитів. Без знання бази неможливо відрізнити якісний тест від «галюцинації» алгоритму.
Міф 3: AI-моделі ніколи не помиляються в асертах (перевірках)
Існує термін AI Bias (упередженість ШІ). Якщо модель навчалася на застарілих даних, вона може вважати помилку «нормальною поведінкою».
Наприклад, якщо в попередніх 100 запусках сторінка завантажувалася 5 секунд, AI може не позначити це як баг продуктивності, сприйнявши за еталон. У 2026 році контроль еталонів (oracles) залишається критичною функцією людини, щоб уникнути накопичення технічного боргу, схваленого штучним інтелектом.
Хто знає, можливо, деякі з цих міфів колись і стануть нашою реальністю, адже межа між фантазією та технологіями стирається швидше, ніж ми встигаємо оновлювати ПЗ. Про те, як кінематограф передбачив сучасні виклики та які сценарії вже втілилися в життя, читай у статті: «5 фільмів, що лякаюче точно передбачили наше технологічне майбутнє».
Які задачі AI уже реально забирає у QA
Штучний інтелект у тестуванні найшвидше заходить там, де багато повторюваних дій та технічної рутини. У 2026 році це вже не експерименти, а стандарт індустрії. Компанії, що впровадили AI-driven підхід, звітують про скорочення загального часу тестування на 70% (згідно з останніми галузевими звітами).
Створення тестових сценаріїв
Один із найпомітніших напрямів — автоматичне формування сценаріїв. AI аналізує інтерфейс та типові шляхи користувача, пропонуючи готову логіку перевірки.
За даними звіту Capgemini, використання генеративного AI для створення тест-кейсів дозволяє скоротити час на ручне написання скриптів на 50–60%. Система самостійно:
Визначає критичні точки перевірки на основі бізнес-логіки.
Формує базові позитивні та негативні сценарії.
Автоматично готує пакет тестування після оновлення продукту.
Підтримка локаторів після змін інтерфейсу
Ще недавно зміна навіть одного ID кнопки зупиняла автоматизацію. Тепер AI використовує аналіз структури сторінки та контекст, щоб знайти об’єкт навіть після зміни технічного ідентифікатора.
На цьому принципі базується Self-healing (самовідновлення). Дослідження показують, що цей механізм знижує витрати на підтримку (maintenance) тестів на 70%. Замість ручного виправлення коду, система аналізує текст, розташування та сусідні елементи, щоб «вилікувати» тест у реальному часі.
Аналіз нестабільних перевірок
Окрема зона ефективності — боротьба з «флекі-тестами» (flaky tests). Часто перевірка падає не через баг, а через затримку мережі або нестабільність середовища.
AI допомагає миттєво відрізнити «технічний шум» від справжньої помилки. Це дозволяє командам на 40% швидше проводити тріаж (сортування) багів, не витрачаючи години на розбір логів, які виявилися помилковими спрацьовуваннями.
Де людина поки сильніша
Попри прогрес, AI слабко працює там, де потрібне розуміння емоційного досвіду. Алгоритм може перевірити послідовність кроків, але не помітить «незручну» логіку або дискомфорт користувача.
За прогнозами Forrester, до кінця 2026 року 70% бюджетів на QA включатимуть тестування клієнтського досвіду (CX), де людська емпатія залишається незамінною.
Тепер, коли ми побачили цифри ефективності, логічно перейти до головної «зірки» сучасного QA — механізму самовідновлення. Розберемося, чому саме самовідновлення (self-healing) називають головною революцією, яка нарешті зробила автоматизацію по-справжньому надійною.
Самовідновлення: чому цей механізм став головною революцією у QA
Ще кілька років тому будь-яка дрібна зміна в інтерфейсі могла зупинити десятки автоматизованих перевірок. Достатньо було змінити технічний ідентифікатор кнопки або назву поля вводу — і сценарій «падав», хоча для користувача все працювало справно.
Через це підтримка автоматизації раніше займала до 30–40% усього робочого часу команди. Створення нових перевірок часто відкладалося через необхідність «лікувати» старі скрипти.
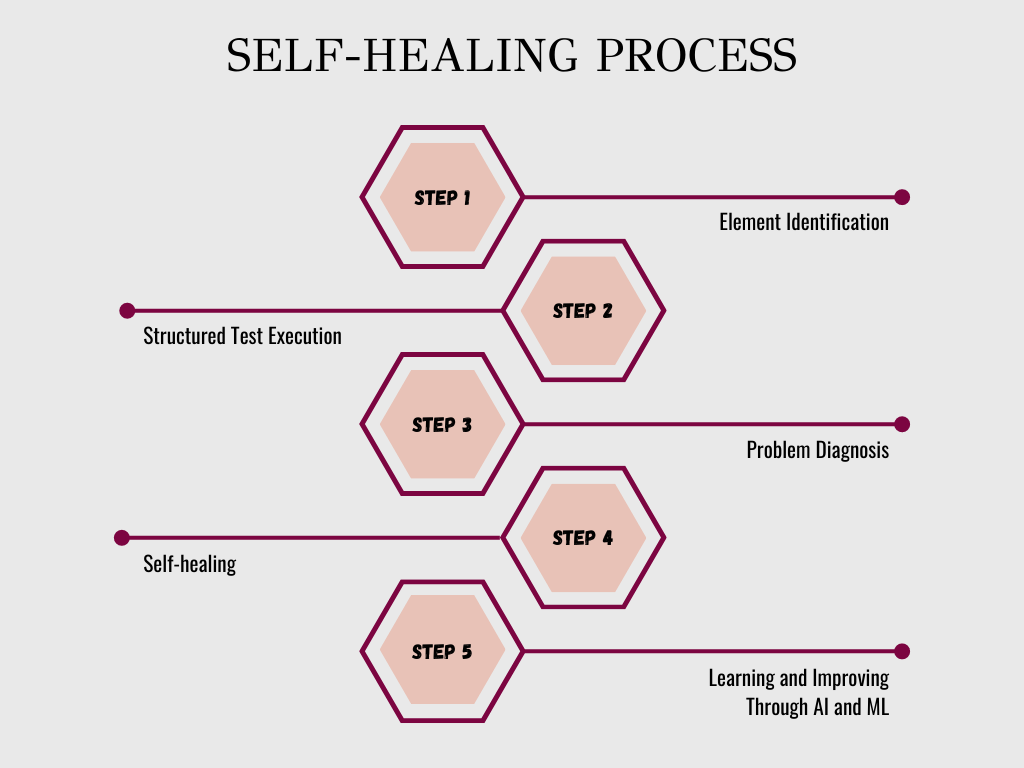
Механізм самовідновлення розв’язує цю проблему інакше. Система не шукає елемент лише за одним технічним параметром, а аналізує одразу сукупність ознак. Якщо одна характеристика змінилася, штучний інтелект використовує інші орієнтири, щоб знайти потрібний об’єкт.
Як працює автоматичне корегування тестів
Під час запуску система проводить багатофакторний аналіз. Вона враховує текст елемента, його точне розташування на сторінці та сусідні блоки. Також аналізується тип очікуваної дії та вся попередня історія успішних проходжень.
Наприклад, кнопка «Оплатити» змінила внутрішню назву в коді, але залишилася на тому самому місці. Штучний інтелект розпізнає її за непрямими ознаками та завершує перевірку без зупинки. Це дозволяє уникнути «технічного шуму» в звітах.
Чому це критично важливо у 2026 році
Сьогодні інтерфейси змінюються динамічно: дизайн-команди оновлюють компоненти, а розробники постійно переносять блоки. Без механізму самовідновлення кожне таке оновлення запускало б ланцюг виснажливих ручних виправлень у коді тестів.
Згідно з останніми дослідженнями Tricentis, впровадження самовідновлення дозволяє:
Скоротити витрати часу на підтримку тестів на 70–80%.
Зменшити кількість хибних падінь (false positives) на 45%.
Вдвічі швидше запускати повторне тестування після великих релізів.
Великі платформи тестування вже зробили цю функцію базовою. Тепер стабільність автоматизації залежить не від якості написаного коду, а від навченості моделі, яка його супроводжує.
Межі можливостей технології
Автоматика відновлює технічну стабільність, але вона не здатна оцінити логіку продукту з погляду здорового глузду. Система може успішно пройти сценарій навіть тоді, коли користувач стикається з явним дискомфортом.
Штучний інтелект поки не помітить зайвий крок у кошику або нелогічний порядок дій. Саме тому після етапу технічної стабільності ми переходимо до складнішого рівня. У 2026 році його називають агентним тестуванням (agentic testing), де алгоритм сам ухвалює рішення про стратегію перевірки.
Агентне тестування: коли AI не просто допомагає, а ухвалює рішення
Якщо самовідновлення навчило систему підтримувати стабільність після змін інтерфейсу, то наступний етап пішов значно далі. У 2026 році штучний інтелект почав самостійно визначати пріоритети: що саме потребує перевірки після чергового оновлення коду.
Такий підхід називають агентним тестуванням (agentic testing). У цій моделі AI працює як автономний агент, який інтегрований у процес контролю якості та здатний до самостійного планування дій.
На практиці система аналізує зміни в репозиторії, історію попередніх помилок та реальну поведінку користувачів. На основі цих даних вона визначає, який функціональний блок має найвищий ризик після релізу. Сучасні платформи вже вміють не просто запускати скрипти, а формувати нові послідовності дій, адаптуючись до логіки продукту.
Чим агентне тестування відрізняється від класичної автоматизації
У класичній моделі сценарій повністю задає людина: маршрут по сторінках, кожна кнопка та очікуваний результат (assertion) прописані вручну. В агентній моделі AI бере на себе роль інтелектуального штурмана. Система здатна:
Самостійно дослідити новий функціональний блок.
Визначити зони найбільшого технічного та бізнес-ризику.
Сформувати оптимальний маршрут перевірки «на льоту».
Запропонувати пріоритетність запусків для економії часу та ресурсів.
Фактично штучний інтелект переходить від ролі технічного виконавця до ролі активного партнера у забезпеченні якості.
Порівняння інструментів з елементами агентного підходу
Інструмент
Ключова можливість
Рівень автономності
Для кого найкраще підходить
Applitools
Візуальний аналіз та порівняння змін
Високий (UX/UI)
Команди з фокусом на інтерфейс
Tricentis
Прогностична аналітика та аналіз ризиків
Екстремальний (Enterprise)
Великі корпоративні системи
QA Wolf
Автономне створення наскрізних перевірок
Високий (Full-service)
Продукти, що швидко ростуть
Mabl
Аналіз нестабільності та самовідновлення
Середній (Web/API)
SaaS та вебсервіси
Testim
Швидке формування сценаріїв з AI-підказками
Середній (Low-code)
Гнучкі Agile-команди
Де агентне тестування дає найбільший ефект
Найкраще цей підхід працює в умовах Continuous Deployment (безперервного розгортання), де релізи відбуваються кілька разів на день. Замість повного регресійного тестування, яке може тривати години, AI обирає лише критичні 10–15% сценаріїв, які дійсно могли постраждати від змін. Це дозволяє:
Скоротити час виходу продукту на ринок (Time-to-Market) на 40–50%.
Виявляти критичні дефекти на ранніх етапах завдяки аналізу вразливих зон.
Звільнити команду від рутинного планування однакових тестів.
Чому роль спеціаліста стає критичнішою
Попри високу автономність, штучний інтелект не розуміє бізнес-наслідків помилки так, як людина. Алгоритм може вказати на технічний збій, але не здатний оцінити, як дрібна неточність вплине на лояльність клієнтів або репутацію бренду.
Роль QA-фахівця зміщується на рівень вище: від написання кроків — до управління стратегією, пріоритетами та валідації рішень, які пропонує AI. Це вимагає нових навичок, які допоможуть не просто залишатися в професії, а керувати цим технологічним стрибком.
Як QA-спеціалісту не залишитись без роботи у 2026 році
Трансформація індустрії не означає скорочення професії, проте вона вимагає докорінного оновлення навичок. Механічне виконання тест-кейсів остаточно відходить у минуле, поступаючись місцем стратегічному управлінню якістю.
Головна зміна в професії полягає в тому, що дорожчає зовсім інший тип компетенцій. Раніше ринок високо оцінював здатність вручну виконувати великі обсяги перевірок. Тепер роботодавці шукають спеціалістів, які працюють на рівні логіки продукту та аналізу ризиків.
Виграють ті, хто сприймає AI як інструмент, що забирає технічну рутину. У 2026 році сильний фахівець — це не просто виконавець сценаріїв. Це людина, яка розуміє, де алгоритм помиляється, і які перевірки є критичними для бізнесу.
Навички, що мають найбільшу цінність
Ринок найшвидше підсилює тих, хто розвиває комплексні напрями. Найбільшу конкурентну перевагу сьогодні дають:
Глибока аналітика технічної логіки: розуміння архітектури продукту та зв’язків між сервісами.
AI-грамотність: вміння налаштовувати агентні системи та правильно інтерпретувати їхні звіти.
Прогностична оцінка ризиків: здатність визначити наслідки збою ще до виходу в реліз.
Особливо важливо вміти верифікувати результат роботи нейромереж, а не просто довіряти йому. Система може запропонувати тисячі сценаріїв, але саме людина визначає їхню релевантність для бізнес-цілей.
Що перестає бути достатнім для кар’єрного росту
У ручному тестуванні найбільший ризик виникає там, де робота обмежується лише повторюваними діями. Просте проходження чек-листа стає частиною того, що AI виконує швидше та значно дешевше.
Сьогодні ринок найнижче оцінює відсутність розуміння принципів автоматизації та небажання опановувати нові платформи. Залишатися виключно в зоні мануальних перевірок без аналізу продукту — це прямий шлях до втрати конкурентності.
Головна стратегія успіху
Найсильніший спеціаліст у 2026 році поєднує технічне мислення та бачення кінцевого користувача. У цій точці AI поки не може повністю замінити людину, бо алгоритм не відчуває емоційного ефекту від помилки.
Машина не оцінить втрату довіри до продукту через невдало сформульоване повідомлення. Тому головна стратегія проста: не боротися зі штучним інтелектом, а працювати в зоні, де він підсилює швидкість, а людина гарантує якість рішення.
Підсумуємо
У 2026 році тестування за допомогою штучного інтелекту остаточно перетворилося з теорії на робочий інструмент. Технології самовідновлення та агентний підхід успішно взяли на себе технічну рутину, звільнивши спеціалістів від нескінченної підтримки застарілих сценаріїв. Проте автоматизація не замінила людину, а змістила фокус її роботи на складніші задачі. Сьогодні цінність QA-фахівця визначається здатністю бачити продукт як цілісну систему, розуміти бізнес-логіку та контролювати якість там, де алгоритми бачать лише набір функцій.
Найкращий спосіб не просто підлаштовуватися під зміни, а впевнено керувати ними — це розуміти, як продукт будується з нуля. Глибокі знання архітектури дозволяють налаштовувати AI-інструменти значно точніше та бачити зони ризику ще на етапі написання коду. Опанувати це можна на курсі «Fullstack розробник», де ми навчимо тебе створювати сучасні рішення від інтерфейсу до серверної логіки. Це фундамент, який перетворює тестувальника на повноцінного інженера, здатного проектувати та забезпечувати якість цифрових продуктів будь-якої складності.
FAQ`s
Чи означає впровадження AI, що ручне тестування (Manual QA) остаточно зникне?
Ні, ручне тестування трансформується в дослідницьке та UX-тестування. AI чудово справляється з перевіркою технічних параметрів, але він не здатний оцінити зручність інтерфейсу чи емоційний досвід користувача.
Які мови програмування варто вчити QA-спеціалісту у 2026 році, якщо AI сам пише код?
Знання бази JavaScript/TypeScript або Python залишається критичним. Хоча AI генерує скрипти, інженер має вміти їх читати, проводити ревізію (code review) та виправляти архітектурні помилки. Без розуміння коду неможливо валідувати результати роботи нейромережі та відрізнити якісний тест від «галюцинації».
Чим Agentic testing відрізняється від звичайної автоматизації, яку ми знали раніше?
Класична автоматизація виконує лише те, що чітко прописав інженер (крок за кроком). Агентне тестування — це автономна система, яка сама аналізує зміни в коді, визначає зони ризику та самостійно вирішує, які сценарії запустити саме зараз, щоб гарантувати стабільність релізу.
Чи правда, що AI-інструменти часто помиляються і їм не можна довіряти на 100%?
Так, існує термін «AI Bias» (упередженість ШІ). Якщо система навчалася на застарілих даних, вона може сприймати помилку за еталон. Саме тому у 2026 році головною навичкою QA стає верифікація рішень штучного інтелекту — людина завжди залишається фінальним арбітром.
Які навички QA найцінніші у 2026 році?
Найбільше цінуються розуміння автоматизації, робота з AI-інструментами, аналіз ризиків і здатність бачити продукт ширше за окремий тестовий сценарій.
Глосарій до статті
AI Bias (Упередженість ШІ) — систематична помилка в алгоритмах, коли модель через застарілі дані може сприймати дефект (наприклад, повільне завантаження) як нормальну поведінку системи.
AI-driven testing — сучасний підхід, де штучний інтелект бере на себе рутину: від генерації сценаріїв до адаптації тестів під зміни в продукті.
Agentic testing (Агентне тестування) — автономний рівень тестування, де AI діє як «агент», самостійно вирішуючи, які саме функції та сценарії потребують перевірки після оновлення.
Continuous Deployment (CD) — процес безперервного розгортання коду, який вимагає від QA максимальної швидкості перевірок, що забезпечується саме інструментами AI.
DOM-структура (Document Object Model) — технічна ієрархія елементів вебсторінки, яку AI аналізує для точного пошуку об’єктів (кнопок, полів) незалежно від їхнього візуального вигляду.
Flaky tests (Флекі-тести) — нестабільні перевірки, що періодично «падають» без об’єктивної помилки в коді (наприклад, через мережеві лаги), і які AI допомагає фільтрувати.
Low-code інструменти — платформи для автоматизації, що дозволяють створювати тести з мінімальним написанням коду, використовуючи візуальні інтерфейси та підказки ШІ.
Self-healing (Самовідновлення) — функція, завдяки якій автотест самостійно виправляється, якщо розробники змінили технічні параметри елемента (ID або CSS-клас).
Time-to-Market — швидкість виходу продукту від ідеї до релізу; головний показник, який AI-driven testing допомагає покращити на 40–50%.
Visual AI — технологія візуального аналізу, що дозволяє системі порівнювати інтерфейс за принципом «людського ока», ігноруючи технічні зміни в коді, які не впливають на вигляд.
Галюцинація ШІ — помилкова генерація сценаріїв або коду нейромережею, яка виглядає технічно правильною, але не відповідає реальній логіці продукту.
Клієнтський досвід (CX) — емоційне та функціональне враження користувача від продукту, оцінка якого у 2026 році залишається виключною прерогативою людини.
Регресійне тестування — повторна перевірка вже готового функціоналу, яку AI оптимізує, обираючи лише ті зони, що реально могли постраждати від нових змін.
Тріаж багів (Bug Triage) — процес швидкого сортування та пріоритезації помилок, який за допомогою AI стає на 40% швидшим завдяки відсіюванню технічного шуму.
Якісні еталони (Oracles) — визначені людиною критерії «правильної» поведінки системи, за якими вона перевіряє роботу AI, щоб уникнути накопичення помилок.
Від написання коду до управління AI-агентами: як трансформується роль тестувальника у 2026 році. Аналізуємо головні виступи RoboCon у Гельсінкі — від «млинцевого тестування» до нових стандартів сертифікації.